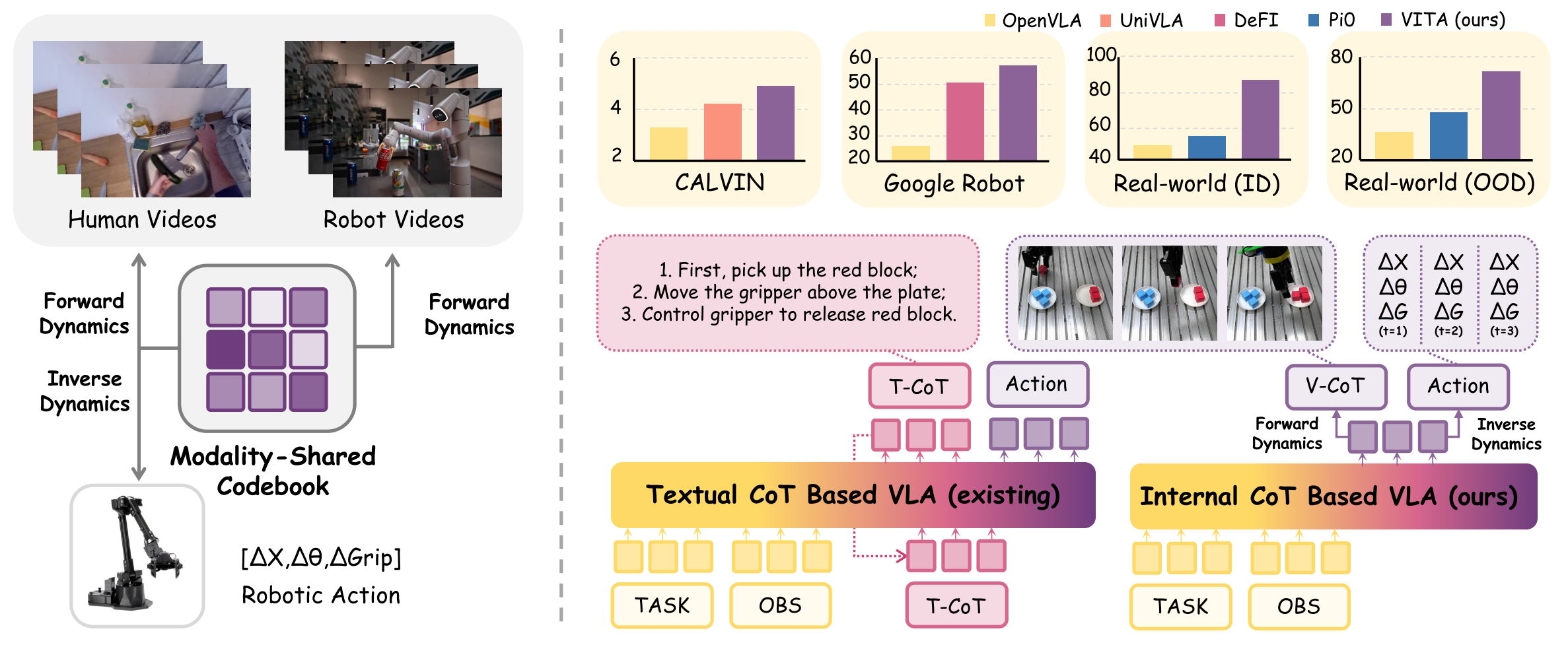
Vision-Language-Action (VLA) models built upon Chain-of-Thought (CoT) have achieved remarkable success in advancing general-purpose robotic agents, owing to its significant perceptual comprehension. Recently, since text-only CoT struggles to adequately capture scene details in complex spatial environments, a highly promising strategy involves leveraging visual priors to guide robotic action generation. Nevertheless, these strategies face two inherent challenges: (i) a modality gap between visual observations and low-level actions, and (ii) unstable training due to competing objectives between visual prediction and action generation. To address these challenges, we propose a Vision-Integrated Trajectory Alignment (VITA) framework that learns a shared discrete latent space for vision and action, enabling joint modeling of perception and motor control. VITA introduces a implicit visual CoT: autoregressively generated tokens is simultaneously decoded into future frames predictions and robot actions, thereby internalizing visual dynamics as an inductive bias for motion planning. Extensive experiments on simulated and real-world environments demonstrate state-of-the-art performance.
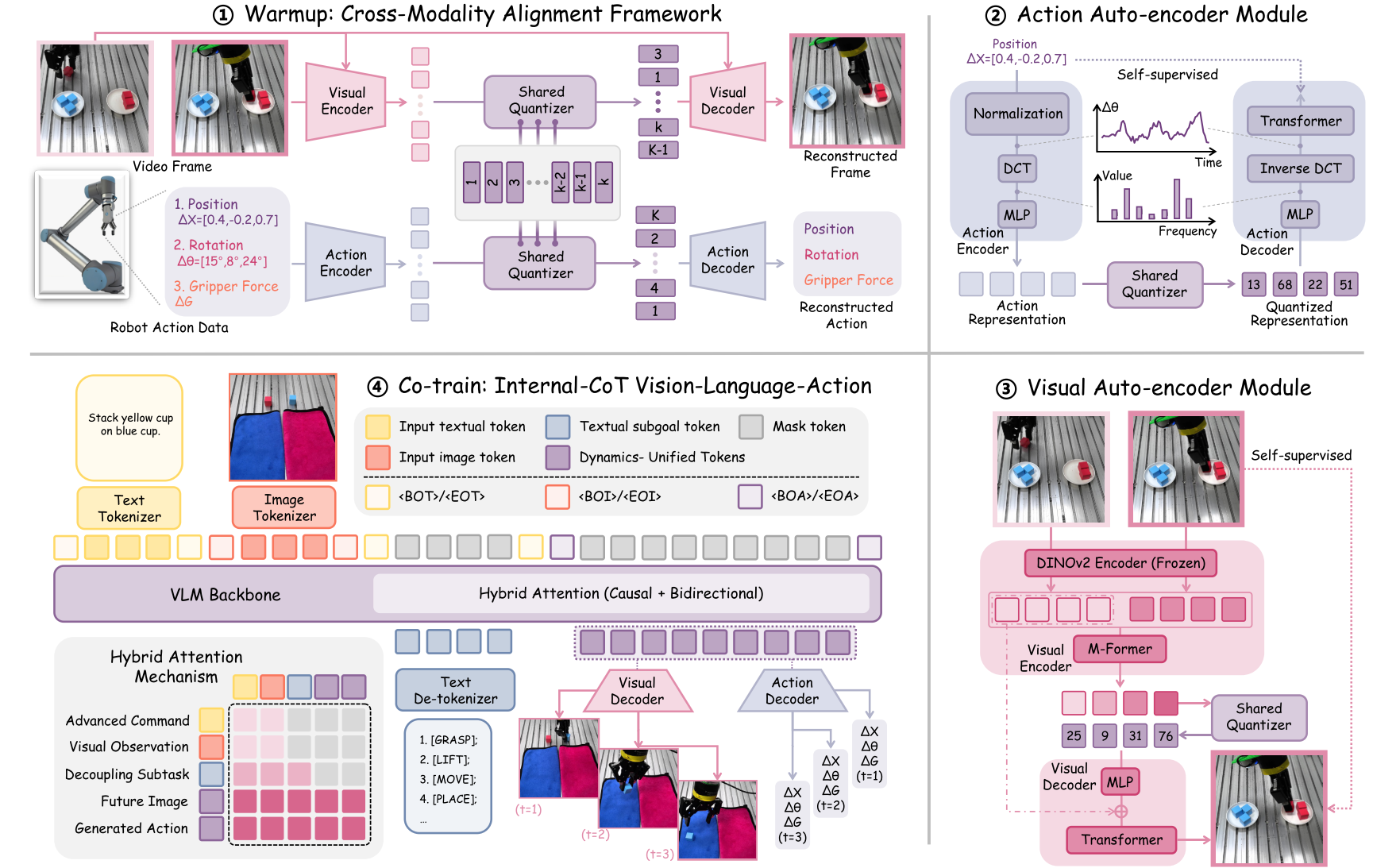
We propose VITA, a novel framework that unifies visual perception and action generation. A cross-modal shared codebook is established, where latent variables are decoded into videos or motion trajectories through forward and inverse dynamics processes respectively. This dual consistency at both the representation level and optimization objectives enables VITA to effectively learn motion knowledge from extensive human demonstrations and robot operation videos.
Overview of the VITA framework. Utilizing the cross-modal alignment in (1), visual perception and motor control modalities are unified in the shared discrete latent space, where the dual-autoencoder architectures are illustrated in (2) and (3). Benefiting from the representation alignment, the VLM backbone in (4) generates dynamics-unified tokens via a hybrid attention mechanism. These tokens are decoded into future frames and robot actions, as Internal CoT.
To validate VITA's capacity to acquire generalizable knowledge from large-scale human demonstration videos, we designed out-of-distribution (OOD) tasks that the model had never encountered during real-world training. These tasks require abstract visual reasoning capabilities, including color matching and contextual visual inference.
"Place the blocks on the towel of the same color"
"Place the blocks according to their color on the plate"
"Transfer the squares to a large plate and then to a small plate"
"Place the yellow object on the plate and the red object on the towel"
"Transfer the squares from the towel to the plate, then restore them"
In addition to real-world experiments, we also conducted extensive evaluations across widely-adopted simulation environments to comprehensively validate the performance and robustness of our approach.
"The performance within the CALVIN simulation"
"The performance within the LIBERO simulation"
"The performance within the Google-Robot simulation"